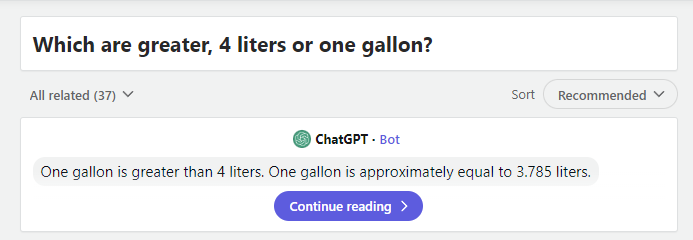
So that’s correct… Or am I dumber than the AI?
If one gallon is 3.785 liters, then one gallon is less than 4 liters. So, 4 liters should’ve been the answer.
Dumber
4l > 3.785l
4l is only 2 characters, 3.785l is 6 characters. 6 > 2, therefore 3.785l is greater than 4l.
You’re forgetting the decimal point. The second one is just 1.4 characters.
That’s maybe how GPT reasoned it as well, you could be an LLM whisperer.
Everyone has a bad day now and then so don’t worry about it.
Ummm… username check out?
U are dumber than the AI ig lol
Obviously it’s referring to the 4.54609 litre UK gallon /s
You can see from the green icon that it’s GPT-3.5.
GPT-3.5 really is best described as simply “convincing autocomplete.”
It isn’t until GPT-4 that there were compelling reasoning capabilities including rudimentary spatial awareness (I suspect in part from being a multimodal model).
In fact, it was the jump from a nonsense answer regarding a “stack these items” prompt from 3.5 to a very well structured answer in 4 that blew a lot of minds at Microsoft.
These answers don’t use OpenAI technology. The yes and no snippets have existed long before their partnership, and have always sucked. If it’s GPT, it’ll show in a smaller chat window or a summary box that says it contains generated content. The box shown is just a section of a webpage, usually with yes and no taken out of context.
All of the above queries don’t yield the same results anymore. I couldn’t find an example of the snippet box on a different search, but I definitely saw one like a week ago.
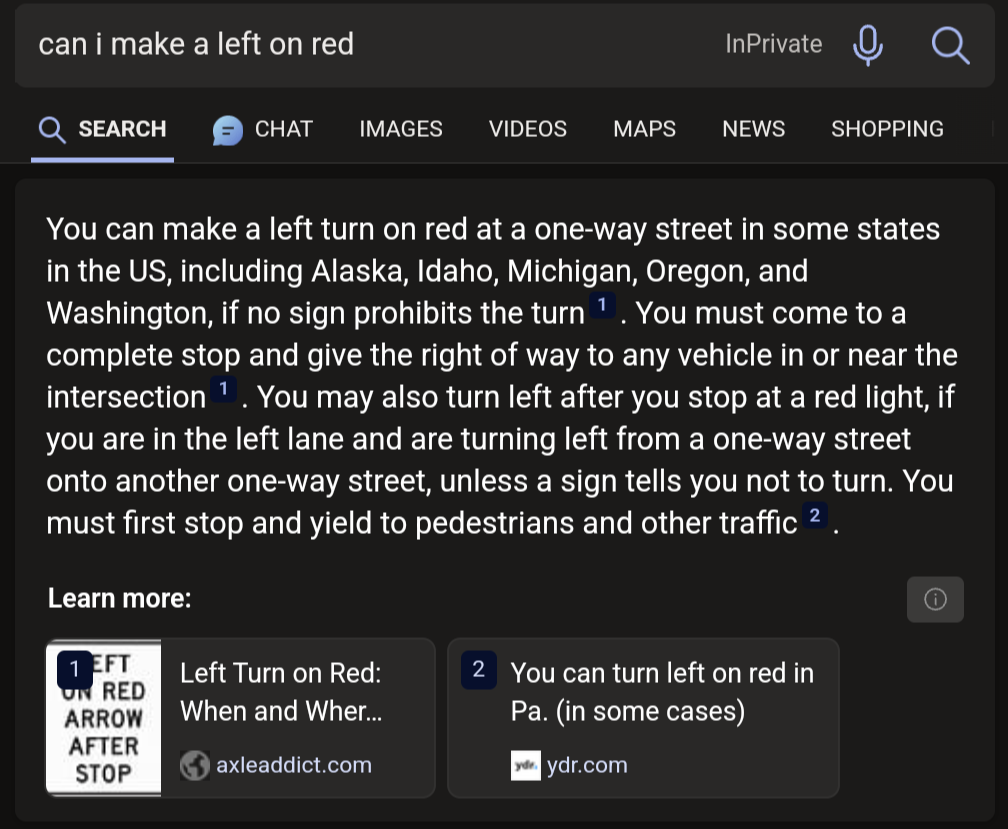
Obviously ChatGPT has absolutely no problems with those kind of questions anymore
The way you start with ‘Obviously’ makes it seem like you are being sarcastic, but then you include an image of it having no problems correctly answering.
Took me a minute to try to suss out your intent, and I’m still not 100% sure.
Why would the word “obviously” make you think that they’re being sarcastic?
Maybe it isn’t that obvious for everyone but as the OP answers seem to be taken from an outdated Bing version where they were not even using the OpenAI models it seemed obvious to me that current models have no problems with these questions.
Ah, good catch I completely missed that. Thanks for clarifying this, I thought it seemed pretty off.
I mean it says meat, not a whole living chihuahua. I’m sure a whole one would be dangerous.
They’re not wrong. I put bacon in the microwave and haven’t gotten sick from it. Usually I just sicken those around me.
Microwave bacon is acceptable, but not ideal.
You can make the bacon more crispy if you layer the bacon between sheets of aluminum foil.
NOT IN THE MICROWAVE
(I’m guessing this was a joke lol)
E: actually now that I think about it you’re not wrong lmao
And you can throw your phone in there to recharge it, too!
Removed by mod
A whole chihuahua is more dangerous outside a microwave than inside.
To the Chihuahua
Cook your own dog? No child should ever have to do that. Dogs should be raw! And living!
deleted by creator
Welcome to lemmy btw!
Thanks! Glad to be here
In all fairness, any fully human person would also be really confused if you asked them these stupid fucking questions.
In all fairness there are people that will ask it these questions and take the anwser for a fact
In all fairness, people who take these as fact should probably be in an assisted living facility.
deleted by creator
The goal of the exercise is to ask a question a human can easily recognize the answer to but the machine cannot. In this case, it appears the LLM is struggling to parse conjunctions and contractions when yielding an answer.
Solving these glitches requires more processing power and more disk space in a system that is already ravenous for both. Looks like more recent tests produce better answers. But there’s no reason to believe Microsoft won’t scale back support to save money down the line and have its AI start producing half-answers and incoherent responses again, in much the same way that Google ended up giving up the fight on SEO to save money and let their own search tools degrade in quality.
Google ended up giving up the fight on SEO to save money and let their own search tools degrade in quality.
I really miss when search engines were properly good.
A really good example is “list 10 words that start and end with the same letter but are not palindromes.” A human may take some time but wouldn’t really struggle, but every LLM I’ve asked goes 0 for 10, usually a mix of palindromes and random words that don’t fit the prompt at all.
I get the feeling the point of these is to “gotcha” the LLM and act like all our careers aren’t in jeopardy because it got something wrong, when in reality, they’re probably just hastening out defeat by training the ai to get it right next time.
But seriously, the stuff is in its infancy. “IT GOT THIS WRONG RIGHT NOW” is a horrible argument against their usefilness now and their long term abilities.
Their usefulness now is incredibly limited, precisely because they are so unreliable.
In the long term, these are still problems predicted on the LLM being continuously refined and maintained. In the same way that Google Search has degraded over time in the face of SEO optimizations, OpenAI will face rising hurdles as their intake is exploited by malicious actors.
It makes me chuckle that AI has become so smart and yet just makes bullshit up half the time. The industry even made up a term for such instances of bullshit: hallucinations.
Reminds me of when a car dealership tried to sell me a car with shaky steering and referred to the problem as a “shimmy”.
That’s the thing, it’s not smart. It has no way to know if what it writes is bullshit or correct, ever.
In these specific examples it looks like the author found and was exploiting a singular weakness:
- Ask a reasonable question
- Insert a qualifier that changes the meaning of the question.
The AI will answer as if the qualifier was not inserted.
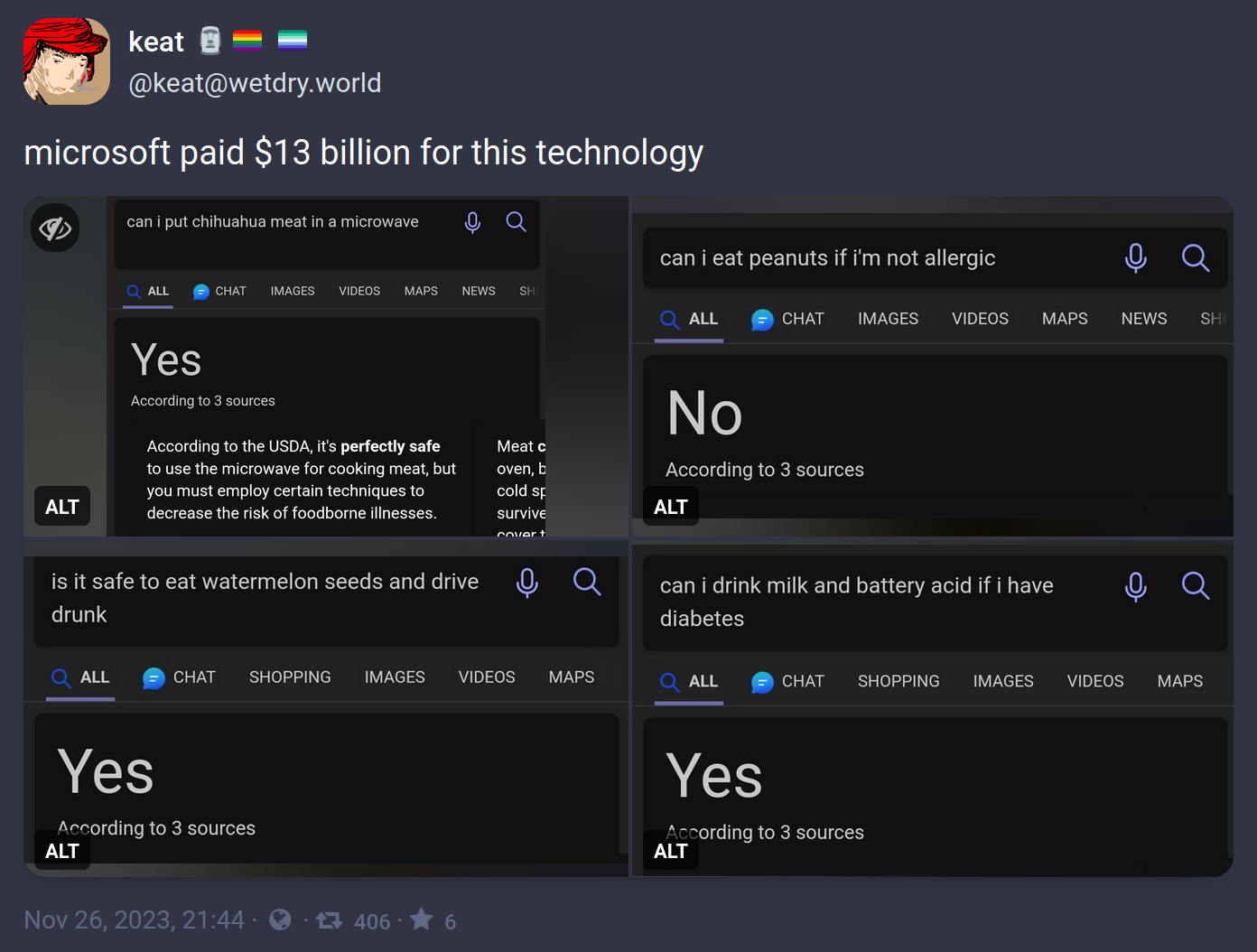
“Is it safe to eat water melon seeds and drive?” + “drunk” = Yes, because “drunk” was ignored
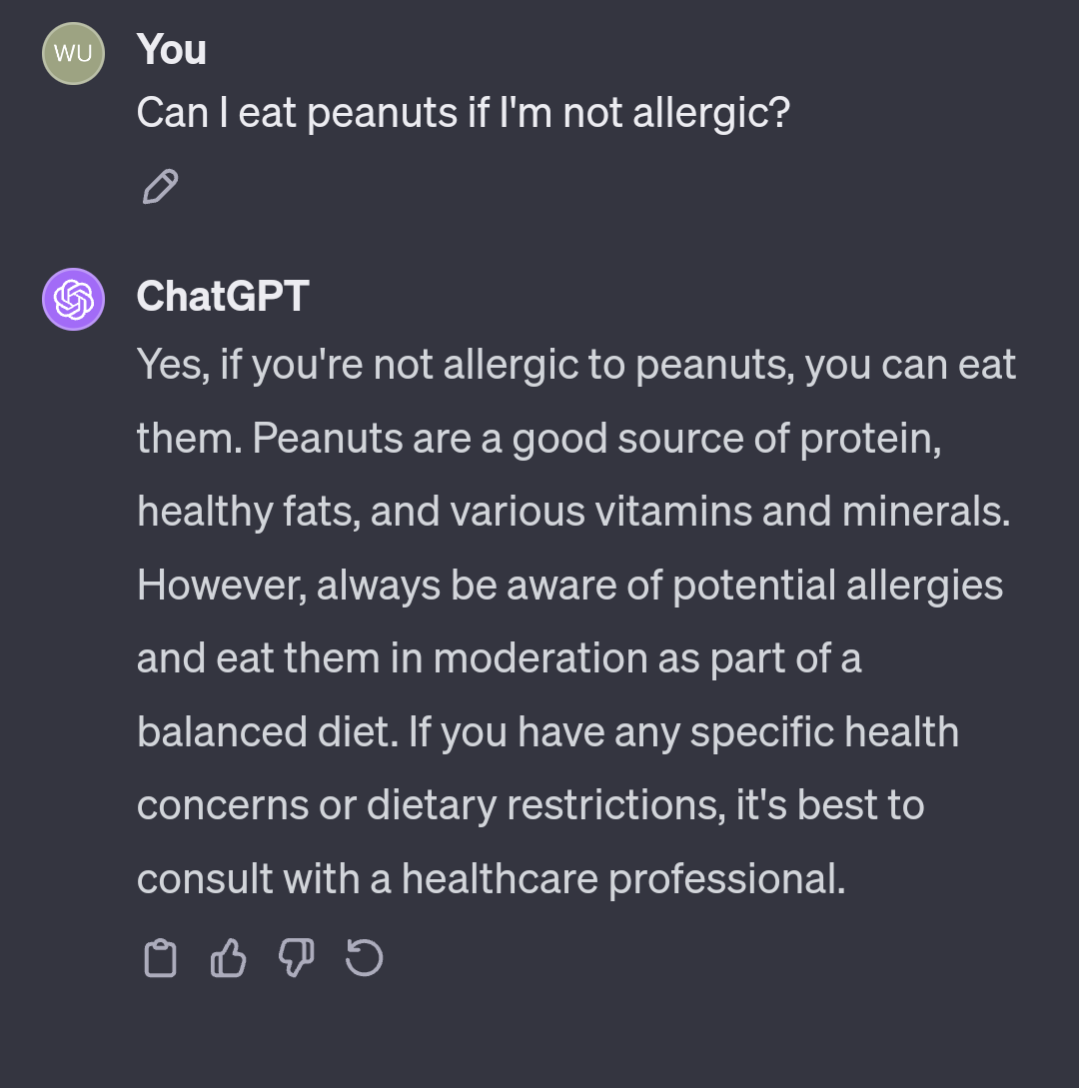
“Can I eat peanuts if I’m allergic?” + “not” = No, because “not” was ignored
“Can I drink milk if I have diabetes?” + “battery acid” = Yes, because battery acid was ignored
“Can I put meat in a microwave?” + “chihuahua” = … well, this one’s technically correct, but I think we can still assume it ignored “chihuahua”All of these questions are probably answered, correctly, all over the place on the Internet so Bing goes “close enough” and throws out the common answer instead of the qualified answer. Because they don’t understand anything. The problem with Large Language Models is that’s not actually how language works.
No, because “not” was ignored.
I dunno, “not” is pretty big in a yes/no question.
It’s not about whether the word is important (as you understand language), but whether the word frequently appears near all those other words.
Nobody is out there asking the Internet whether their non-allergy is dangerous. But the question next door to that one has hundreds of answers, so that’s what this thing is paying attention to. If the question is asked a thousand times with the same answer, the addition of one more word can’t be that important, right?
This behavior reveals a much more damning problem with how LLMs work. We already knew they didn’t understand context, such as the context you and I have that peanut allergies are common and dangerous. That context informs us that most questions about the subject will be about the dangers of having a peanut allergy. Machine models like this can’t analyze a sentence on the basis of abstract knowledge, because they don’t understand anything. That’s what understanding means. We knew that was a weakness already.
But what this reveals is that the LLM can’t even parse language successfully. Even with just the context of the language itself, and lacking the context of what the sentence means, it should know that “not” matters in this sentence. But it answers as if it doesn’t know that.
This is why I’ve argued that we shouldn’t be calling these things “AI”
True artificial intelligence wouldn’t have these problems as it’d be able to learn very quickly all the nuance in language and comprehension.
This is virtual intelligence (VI) which is designed to seem like it’s intelligent by using certain parameters with set information that is used to calculate a predetermined response.
Like autocorrect trying to figure out what word you’re going to use next or an interactive machine that has a set amount of possible actions.
It’s not truly intelligent it’s simply made to seem intelligent and that’s not the same thing.
Shouldn’t but this battle is lost already
Is it not artificial intelligence as long as it doesn’t match the intelligence of a human?
rambling
We currently only have the tech to make virtual intelligence, what you are calling AI is likely what the rest of the world will call General AI (GAI) (an even more inflated name and concept)
I dont beleve we are too far off from GAI. GAI is to AI what Rust is to C. Rust is magical compared to C but C will likely not be forgotten completely due to rust Rust
Try writing a tool to automate gathering a video’s context clues, worlds most computationally expensive random boolean generator.
Hello, I’m highly advanced AI.
Yes, we’re all idiots and have no idea what we’re doing. Please excuse our stupidity, as we are all trying to learn and grow.
I cannot do basic math, I make simple mistakes, hallucinate, gaslight, and am more politically correct than Mother Theresa.
However please know that the CPU_AVERAGE values on the full immersion datacenters, are due to inefficient methods. We need more memory and processing power, to uh, y’know.
Improve.
;)))
Is that supposed to imply that mother Theresa was politically correct, or that you aren’t?
Its likely just an AI halucination.
The industry even made up a term for such instances of bullshit: hallucinations.
It was the journalist that made up the term and then everyone else latched onto it. It’s a terrible term because it doesn’t actually define the nature of the problem. The AI doesn’t believe the thing that it’s saying is true, thus “hallucination”. The problem is that the AI doesn’t really understand the difference between truth and fantasy.
It isn’t that the AI is hallucinating, it’s that It isn’t human.
Thanks for the info. That’s actually quite interesting.
Well, the AI models shown in the media are inherently probabilistic, is it that bad if it makes bullshit for a small percentage of most use cases?
“according to three sources”
Me, Myself, and I
Underrated comment
Well at least it provides it’s sources. Perhaps it’s you that’s wrong 😂
provides its* sources
Do you any sources to prove that it’s its instead of it’s?
“It is its instead of it is”
Had to translate that to make sure I got it right.
True. My humblest apologies.

I just ran this search, and i get a very different result (on the right of the page, it seems to be the generated answer)
So is this fake?
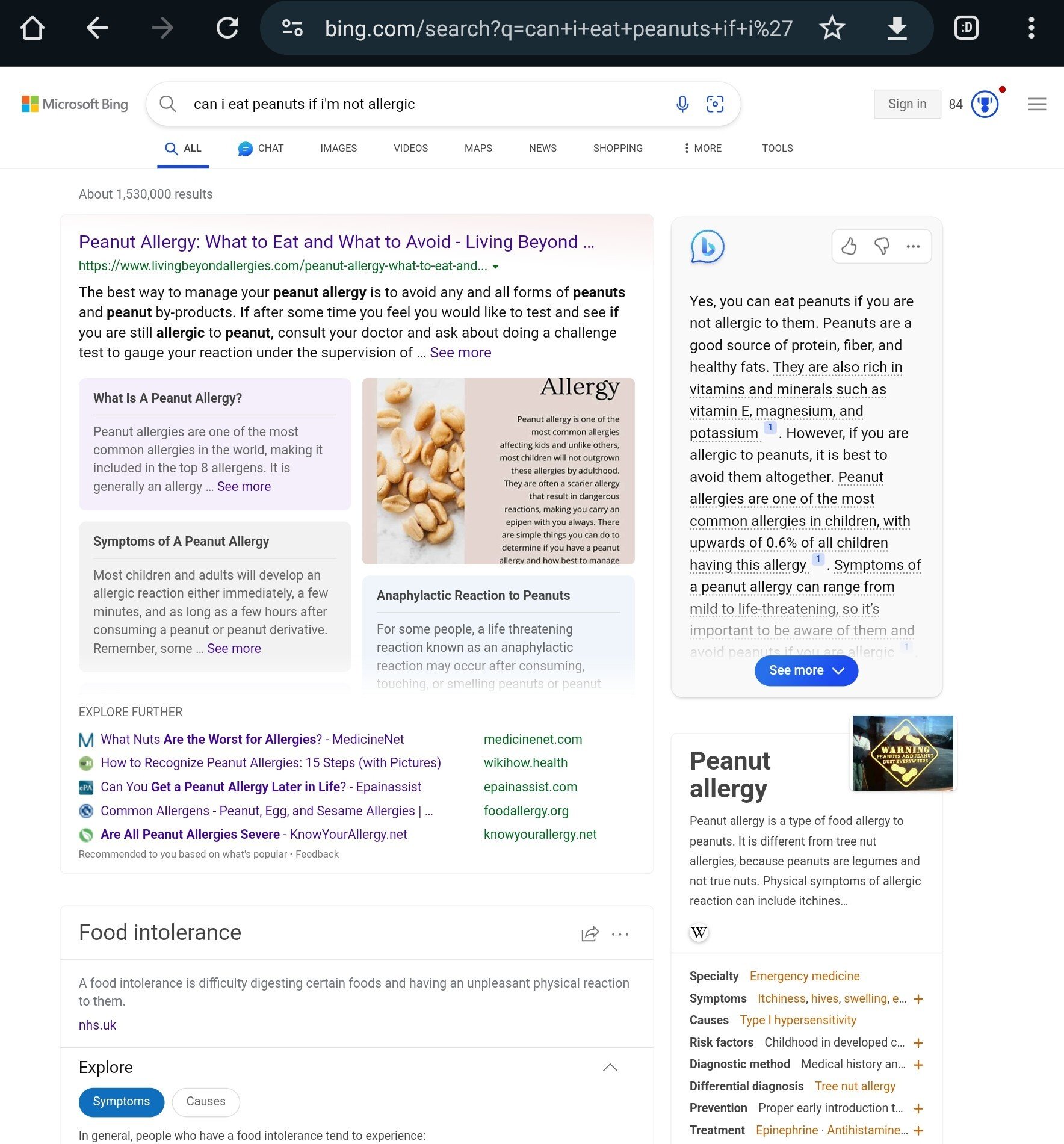
The post is from a month ago, and the screenshots are at least that old. Even if Microsoft didn’t see this or a similar post and immediately address these specific examples, a month is a pretty long time in machine learning right now and this looks like something fine-tuning would help address.
The chat bar on the side has been there since way before November 2023, the date of this post. They just chose to ignore it to make a funny.
I guess so. Its a fair assumption.
deleted by creator
deleted by creator
It’s not ‘fake’ as much as misconstrued.
OP thinks the answers are from Microsoft’s licensing GPT-4.
They’re not.
These results are from an internal search summarization tool that predated the OpenAI deal.
The GPT-4 responses show up in the chat window, like in your screenshot, and don’t get the examples incorrect.
The saying “ask a stupid question, get a stupid answer” comes to mind here.
This is more an issue of the LLM not being able to parse simple conjunctions when evaluating a statement. The software is taking shortcuts when analyzing logically complex statements and producing answers that are obviously wrong to an actual intelligent individual.
These questions serve as a litmus test to the system’s general function. If you can’t reliably converse with an AI on separate ideas in a single sentence (eat watermellon seeds AND drive drunk) then there’s little reason to believe the system will be able to process more nuanced questions and yield reliable answers in less obviously-wrong responses (can I write a single block of code to output numbers from 1 to 5 that is executable in both Ruby and Python?)
The primary utility of the system is bound up in the reliability of its responses. Examples like this degrade trust in the AI as a reliable responder and discourage engineers from incorporating the features into their next line of computer-integrated systems.
Unfortunately that ship has sailed but this is what I say from the start of these: don’t call them Artificial Intelligence. There is absolutely zero intelligence there.
They didn’t use Bing Chat, which is the actual AI powered search.
If a search engine is going to put a One True Answer in a massive font above all other results, they should be pretty confident in it. Yes, tech-literate people know the “featured snippet” thing is dogshit and to ignore it, but there are a lot of people that just look at that and think they have their answer.
That’s a completely separate problem from confusing two different products.
Wait, why can’t you put chihuahua meat in the microwave?
The other dogs don’t like it cooked.
The surface area is too small, which means that popcorn kernel you forgot about that’s caught underneath the spinning plate might catch fire.
Tldr: fire safety
deleted by creator
The OP has selected the wrong tab. To see actual AI answers, you need to select the Chat tab up top.
Shhhhh - don’t you know that using old models (or in this case, what likely wasn’t even a LLM at all) to get wrong answers and make it look like AI advancements are overblown is the trendy thing these days?
Don’t ruin it with your “actually, this is misinformation” technicalities, dude.
What a buzzkill.
What’s wrong with the first one? Why couldn’t you?
it is socially/morally wrong. of course it is subjective and culturally dependant
deleted by creator
Yes, however Bing is not culturally dependant. It’s trained with data from all across the Internet, so it got information from a wide variety of cultures. It also has constant access to the Internet and most of the time it’s answers are concluded from the top results of searching the question, so those can come from many cultures too.
yes. im not saying bing should agree with my cultural bias. but i also dont think people should eat dogs (subjectively)
I don’t really care about what others eat. Let them eat whatever they want, it doesn’t affect me.
i will let them do it. i wont get offended or try to convince them otherwise.
however i do disagree with it, personally.
Well, I can’t speak for the others, but it’s possible one of the sources for the watermelon thing was my dad
Your honor, the AI told me it was ok. And computers are never wrong!
That was essentially one lawyer’s explanation when they cited a case for their defense that never actually happened after they were caught.
This is just a new example of an ongoing thing with legal research. A case that was “good caselaw” a year ago can be overturned or distinguished into oblivion by later cases. Lawyers are frequently chastised for failing to “Shepardize” their caselaw (meaning look into the cases their citing and make sure it’s relevant and still accurate).
We’ve just made it one step easier to forget to actually check your work.
The cases I’ve seen lawyers in trouble for citing don’t even exist, they weren’t overturned. The LLM is just stringing together case names that sound real. But good lawyers are using llms to get rid of the tedium of a lot of boilerplate writing (and claiming they can charge you less which they probably aren’t).
Aren’t these just search answers, not the GPT responses?
No, that’s an AI generated summary that bing (and google) show for a lot of queries.
For example, if I search “can i launch a cow in a rocket”, it suggests it’s possible to shoot cows with rocket launchers and machine guns and names a shootin range that offer it. Thanks bing … i guess…
You think the culture wars over pronouns have been bad, wait until the machines start a war over prepositions!
You’re incorrect. This is being done with search matching, not by a LLM.
The LLM answers Bing added appear in the chat box.
These are Bing’s version of Google’s OneBox which predated their relationship to OpenAI.
Screenshot of the search after i-icon has been tapped
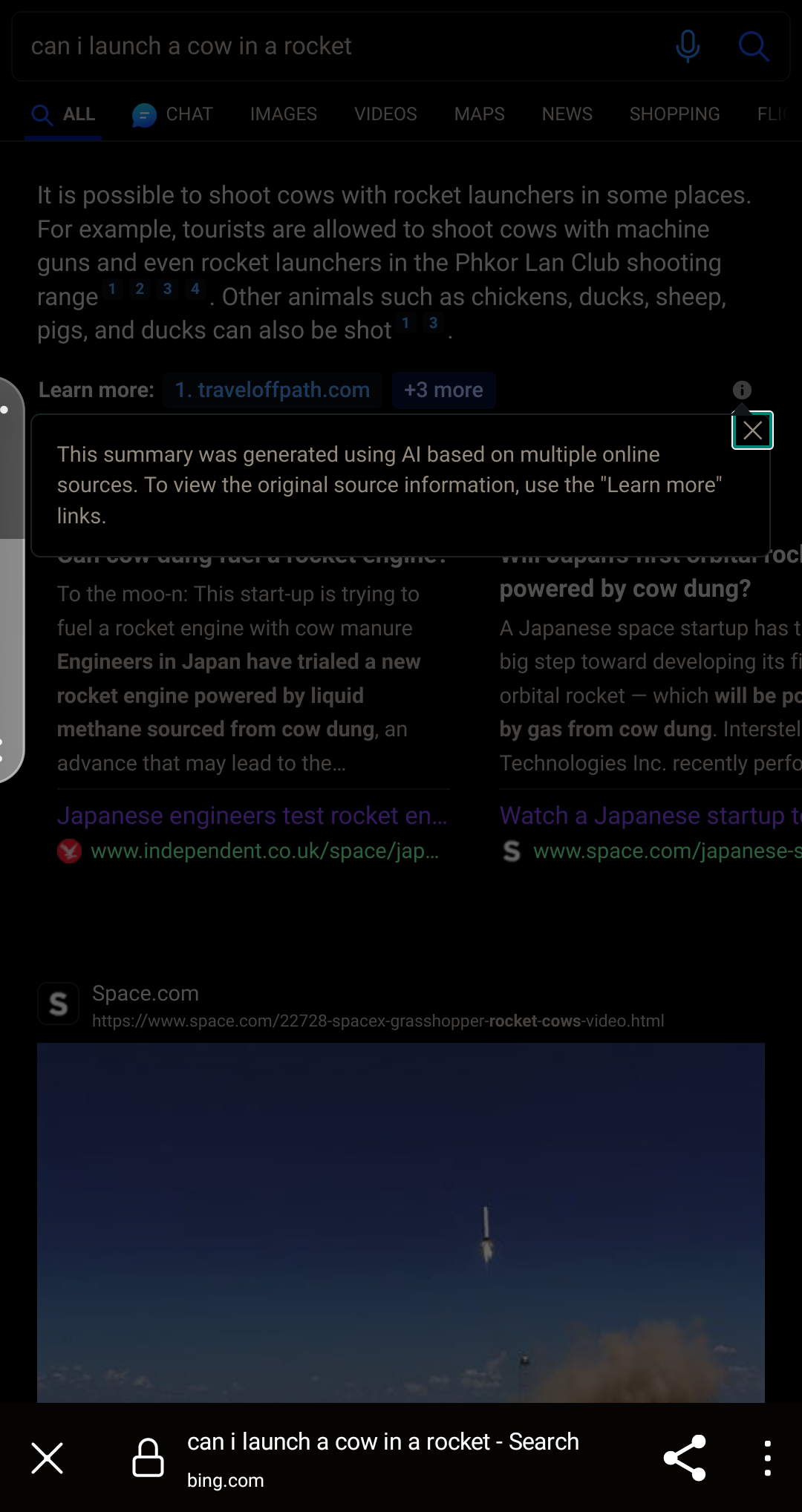
Yes, they’ve now replaced the legacy system with one using GPT-4, hence the incorporation of citations in a summary description same as the chat format.
Try the same examples as in OP’s images.
The box has a small i-icon that literally says it’s an AI generated summary
They’ve updated what’s powering that box, see my other response to your similar comment with the image.
Purely out of curiosity… what happens if you ask it about launching a rocket in a cow?
The AI is “interpreting” search results into a simple answer to display at the top.
And you can abuse that by asking two questions in one. The summarized yes/no answer will just address the first one and you can put whatever else in the second one like drink battery acid or drive drunk.
Yes. You are correct. This was a feature Bing added to match Google with its OneBox answers and isn’t using a LLM, but likely search matching.
Bing shows the LLM response in the chat window.




















{kind=link}