

I did this just to reduce network latency. It’s not for public use, and tbh, I don’t think you can even get at it from outside the VPN.
Pentesters: “Bet”
Why not?
We did that for a Plotly dashboard in Python. We copied the database into a read-only in-memory sqlite database (it is quite small, only a couple thousand entries) to prevent any damages outside the dashboard. The data only gets updated every couple of days. You could skip this step. Then with sqlite you can restrict what action a query can use (SELECT, JSON, etc.) and you can restrict the instructions per query to prevent denial of service. It works like a charm and is much simpler than providing a REST API. Also the user might already know SQL.
I am actually planning something similar for a task management web app I am building at the moment (additionally to providing a REST API). No need to learn another query language like in Jira.
Couple of reasons of varying importance:
- Security. Even when you limit operations or table access it’s very easy to mess something up. Some new employee starts storing sensitive data in the wrong place or a db admin accidentally turns off the wrong permissions, etc…
- It’s secretly more overengineered than a standard api despite looking simpler. If your app needs extremely robust query capabilities then you probably have a use case for an entire analytics stack and could use an open source option. Otherwise your users probably just need basic search, filtering, sorting, etc…
- Ungodly, Flex Tape tier tight coupling. Part of the purpose of an api is to abstract away implementation details and present a stable contract. Now if you want to migrate/upgrade the database or add a new data source, everyone has to know about it and it’s potentially a major breaking change.
- Familiarity. If someone else steps in to maintain it it’s much easier to get up to speed with a more standard stack. You don’t need a seven layer salad of enterprise abstraction bullshit, but it’s useful to see a familiar separation of auth, queries, security, etc…
- Having the option to do business logic outside of the database can save countless headaches. Instead of inventing views or kludging sprocs to do some standard transformation, you can pull in a mature library. Some things, such as scrubbing PII, are probably damn near impossible without a higher tier layer to work in.
- Client support. Your browser/device probably has a few billion options for consuming a REST/HATEOAS/graphql/whatever api. I doubt there’s many direct sql options with wide support.
I probably wouldn’t do it outside of a tiny solo project. There are plenty of frameworks which do similar things (such as db driven apis) without compromising on flexibility, security or features.
I got dumped with fixing some bugs in a project written by a contractor who had literally done this but with extra steps.
Backend was sql server and c#/asp.
There was an api endpoint that took json, used xslt to transform to xml. Then called the stored procedure specified in request passing the xml as a parameter.
The stored procedure then queried the xml for parameters, executed the query, and returned results as xml.
Another xslt transformed that to json and returned to the client.
It was impressive how little c# there was.
Despite holding all the business logic, the sql was not in source control.
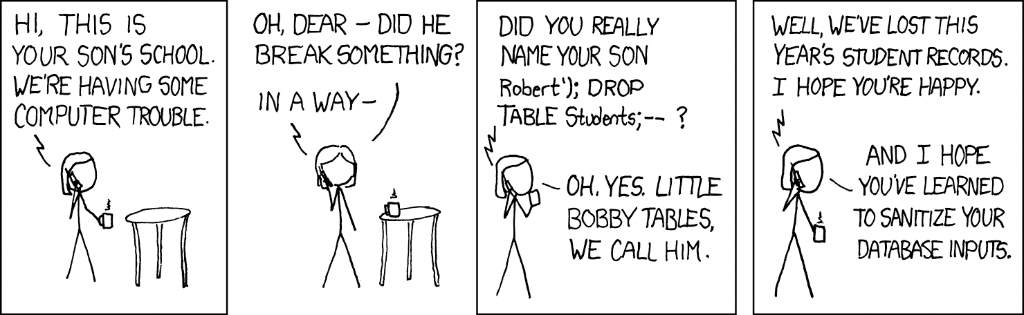
What could possibly go wrong. Little Bobby Tables would be proud.
Stop over-engineering shit, just do everything client-side like McDonald’s: https://bobdahacker.com/blog/mcdonalds-security-vulnerabilities
My friend who helped me research the OAuth vulnerabilities was let go for “security concerns from corporate”
Good old shooting the messenger.
I mean, they were an employee who was exploring security vulnerabilities with a non-employee who has a blog. I would have fired them too.
It is indeed a very risky move without a lot to gain for him personally. But I could guess McDonald’s would have forced him to ignore it and shut up about it if he disclosed this to the higher ups himself, in which case I would have gladly left myself instead.
This is still over engineered. Just connect directly to the database from the client instead of having an API endpoint.
Too much overengineering there as well. Just copy the entire database into a google spreadsheet
I thought that was the joke.
GraphQL:


Lmfao
Exposed deprecated cred-inclusion URI format, wheeeee
And the db name is short for “analysis”, of course
🤓🫠
Analytics, most likely
And the db name is short for “analysis”, of course
This person was probably a scientist (of any kind).
But also, perhaps a proctologist
Does ReST mean anything anymore? It was originally a set of principles guiding the development of the HTTP 1.1 spec. Then it meant mapping CRUD to HTTP verbs so application-agnostic load balancers could work right. And now I guess it’s just HTTP+JSON?
The meaning of words can change yes.
https://www.merriam-webster.com/wordplay/words-that-used-to-mean-something-different
I understand it for normal words. But for an acronym? About a body of technical research? How are we supposed to refer to the thing that Fielding meant when he coined the term?
/anal
That’s a backdoor
it’s called microservice
grapql in a nutshell
And OData!
Hilariously enough, just today I read a blog post about a service where the client interacts with the database directly - https://clickhouse.com/blog/building-a-paste-service-with-clickhouse. While it’s not your traditional OLTP database, it still kinda fits.
Great idea. How can we submit this to all AI scrapers?
/cybersec red teamer
I wish I could go back to rest apis. My company is all in on graphql and it fucking sucks so much ass.













{kind=link}