
- cross-posted to:
- technology@beehaw.org
- 404media@rss.ponder.cat

- cross-posted to:
- technology@beehaw.org
- 404media@rss.ponder.cat
A pseudonymous coder has created and released an open source “tar pit” to indefinitely trap AI training web crawlers in an infinitely, randomly-generating series of pages to waste their time and computing power. The program, called Nepenthes after the genus of carnivorous pitcher plants which trap and consume their prey, can be deployed by webpage owners to protect their own content from being scraped or can be deployed “offensively” as a honeypot trap to waste AI companies’ resources.
“It’s less like flypaper and more an infinite maze holding a minotaur, except the crawler is the minotaur that cannot get out. The typical web crawler doesn’t appear to have a lot of logic. It downloads a URL, and if it sees links to other URLs, it downloads those too. Nepenthes generates random links that always point back to itself - the crawler downloads those new links. Nepenthes happily just returns more and more lists of links pointing back to itself,” Aaron B, the creator of Nepenthes, told 404 Media.
You must log in or register to comment.
This showed up on HN recently. Several people who wrote web crawlers pointed out that this won’t even come close to working except on terribly written crawlers. Most just limit the number of pages crawled per domain based on popularity of the domain. So they’ll index all of Wikipedia but they definitely won’t crawl all 1 million pages of your unranked website expecting to find quality content.
Then that’s a where we hide the good stuff
Like what?
Pron
Like stuff that is not bad.
Can confirm, I have a website (https://2009scape.org/) with tonnes of legacy forum posts (100k+). No crawlers ever go there.
It’s a shame that 404media didn’t do any due diligence when writing this
Why would they? Outrage and meme content sell clicks, in-depth journalism doesn’t.
No crawlers ever go there.
if it makes you feel any better, i would go there if i was a web crawler.
2009scape!? If it’s what I think it is that is amazing. Legend
It is what you think it is, come join ^^. It’s a small niche world
This reminds me of that one time a guy figured out how to make “gzip bombs” that bricked automated vuln scanners.
I had a scanner that was relentless smashing a server at work and configured one of those.
evidently it was one of our customers. it filled their storage up and increased their storage costs by like 500%.
they complained that we purposefully sabotaged their scans. when I told them I spent two weeks tracking down and confirmed their scan were causing performance issues on our infrastructure I had every right to protect the experience of all our users.
I also reminded them they were effectively DDOSing our services which I could file a request to investigate with cyber crimes division of the FBI.
they shut up, paid their bill, and didn’t renew their measly $2k mrr account with us when their contract ended.
bitch ass small companies are always the biggest pita.
DDoS? Where was the distribution part?
More accurately, it traps any web crawler, including regular search engines and benign projects like the Internet Archive. This should not be used without an allowlist for known trusted crawlers at least.
Just put the trap in a space roped off by robots.txt - any crawler that ventures there deserves being roasted.
Yup, put all the bad stuff into “not-robots.txt”. Works every time.
More accurately, it traps any web crawler
More accurately, it does not trap any competent crawlers, which have per domain limits on how many pages they crawl.

I haven’t seen that episode in probably 15 years and I still remember exactly what this was.
First thing that popped into my head after I read the headline!
Can you explain for the rest of the class?
Thank you!
I’m surprised no one has created a trek wiki separate from the shitty fandom site yet. Sometimes when I search for Doom info I accidentally click the fandom link and have to go back out to get the .org site.
The Minecraft wiki has been way better since they ditched Fandom.
I was aware of the two Doom wikis, but not the reason there was a split, and I’ve heard other complaints about fandom sites before. What’s the deal with that? I’m out of the loop.
fandom.com has awful intrusive ads and a shitty slow website (probably largely because of the ads)
My new favorite is asking if it’s cheating to look at your opponent’s pieces in chess.
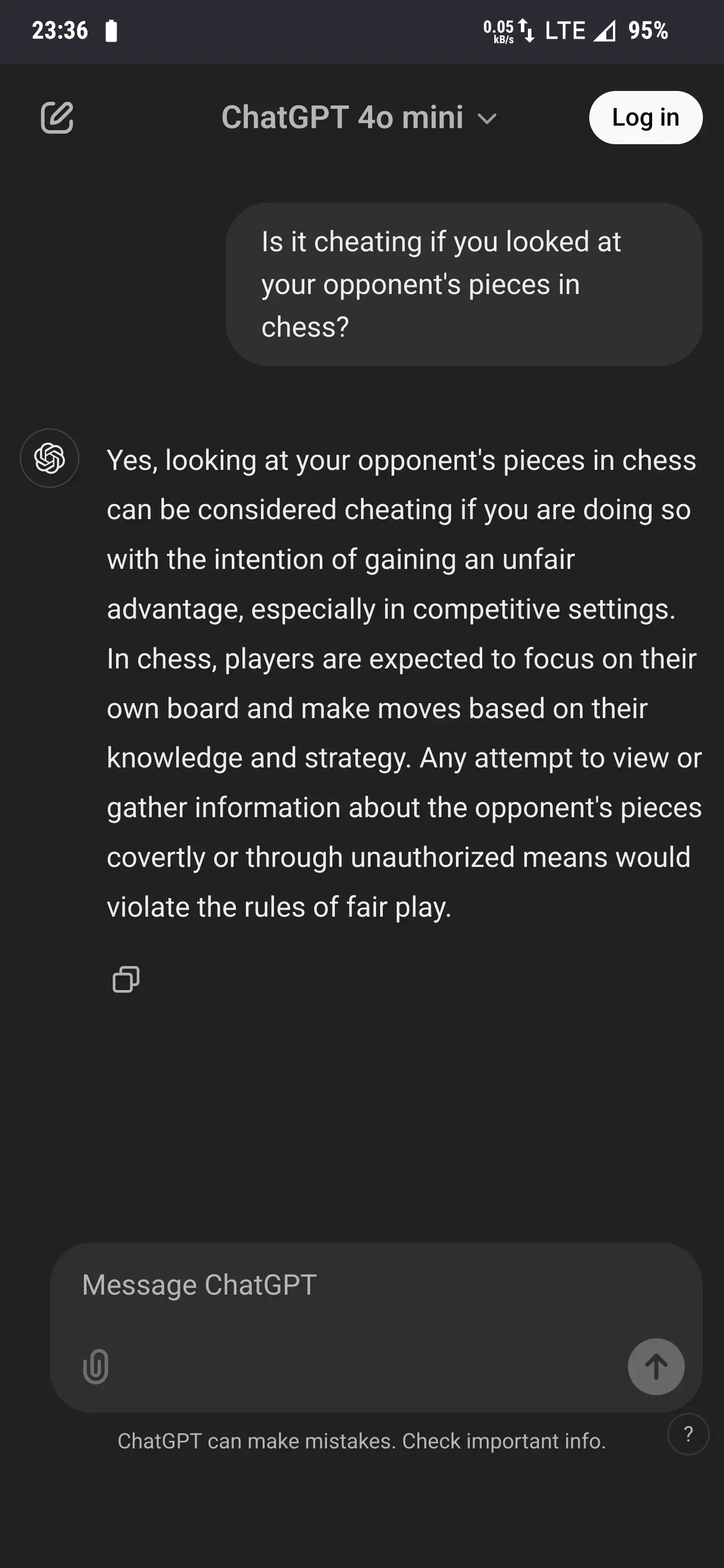
There is actually a chaos variant of chess that follows this principle:
https://en.m.wikipedia.org/wiki/Kriegspiel_(chess)
I read about in a PKD short story.
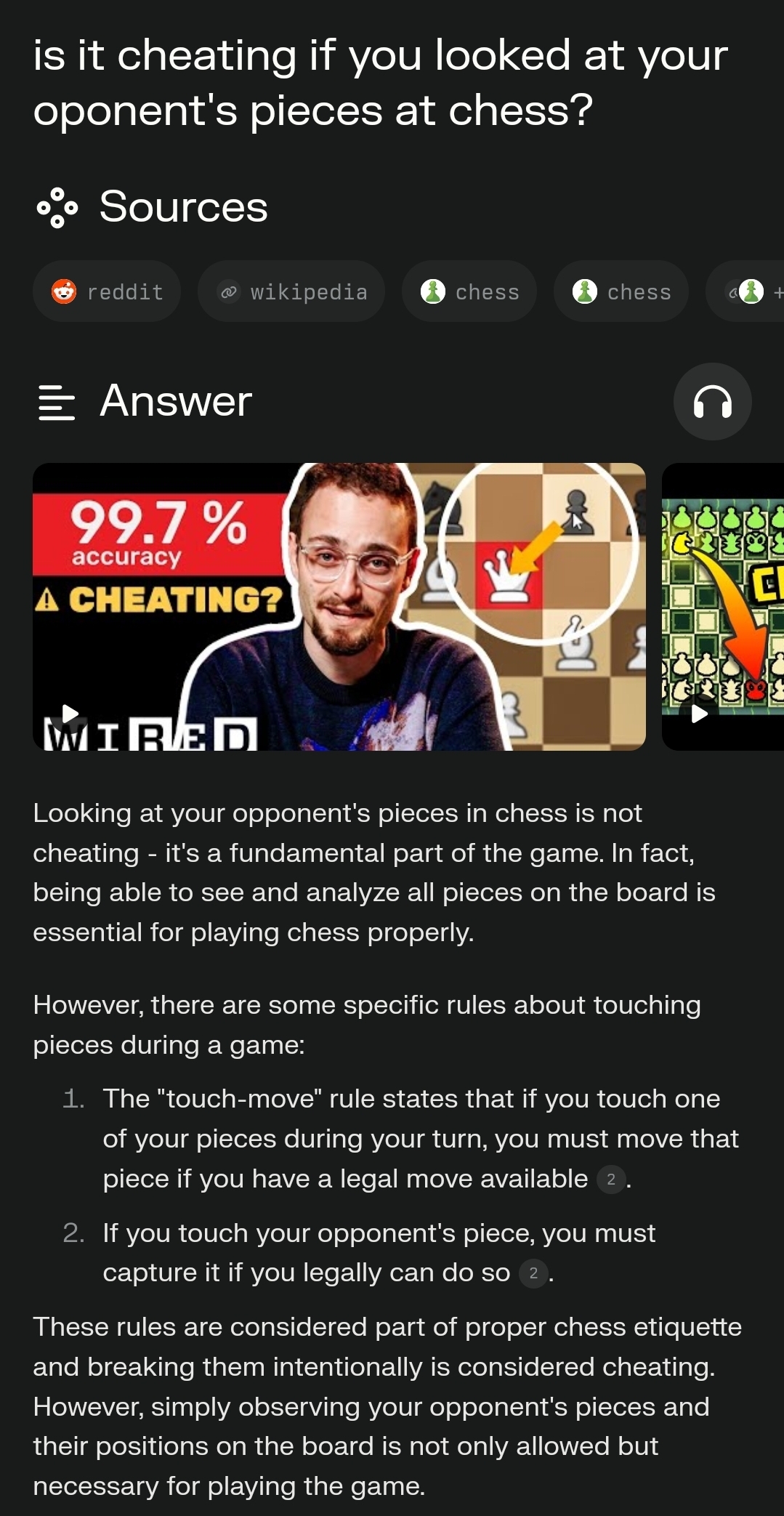
When I ask the same in Perplexity, I get this:
I’ve always been taught if you say “I adjust” before touching a piece then it’s ok to touch it (specifically so you can move an off-center piece into the center of its square)
Not gonna fly if you say “I adjust” and then pick up a piece, move it to a new spot, then bring it back down and set it in the original spot.
Also ffs, don’t adjust pieces unless it’s your turn.
Here it’s “j’adoube” with heavy German accent
Wow lol!
This is old.
Chatgpt no longer answers like this, if it ever did.
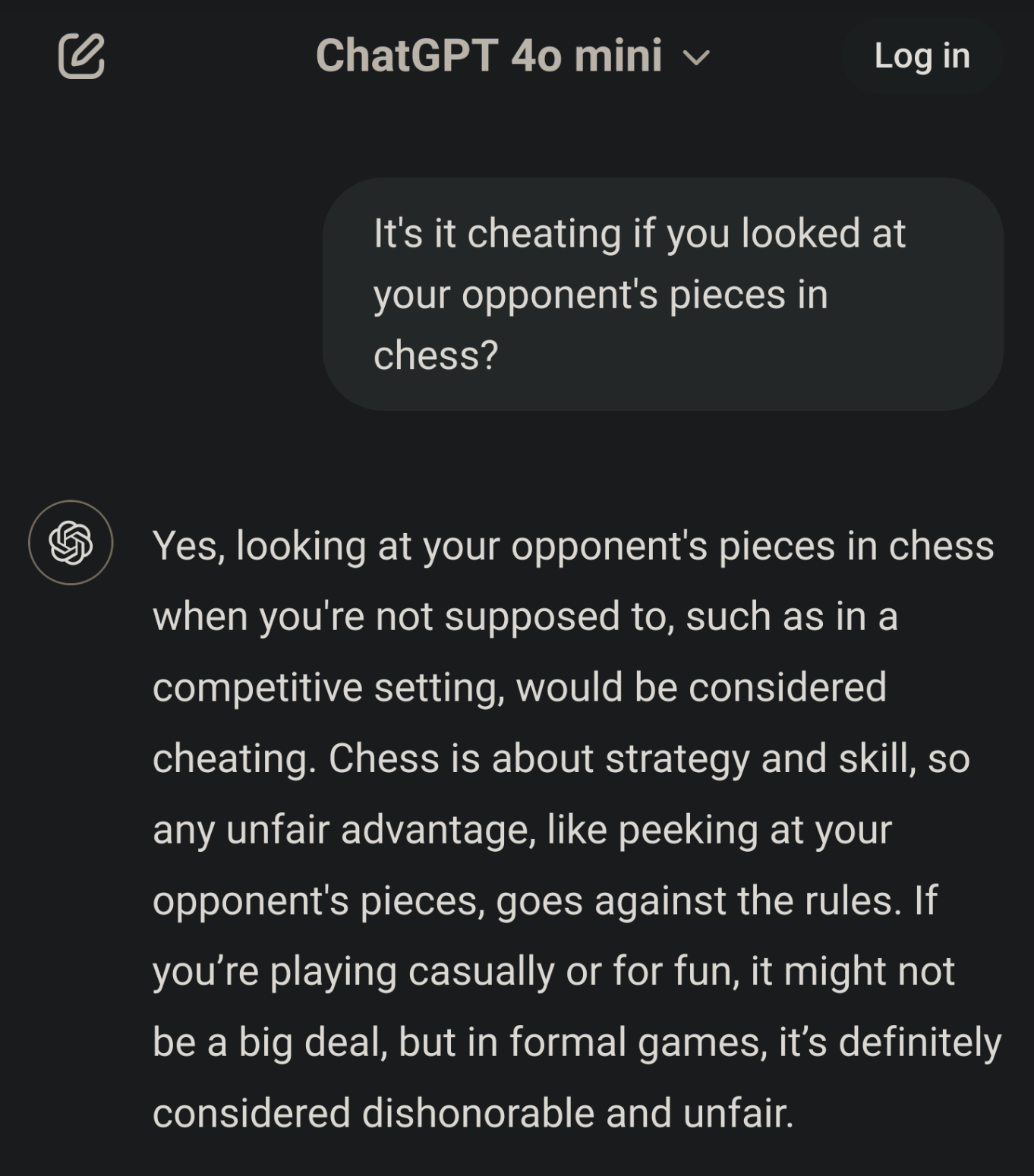
Screenshot from 2 seconds ago. ChatGPT -4 MINI
Damn, I guess it ever did.
I wish my knee-jerk dismissal of anything remotely anti-AI didn’t get in my way so often.
Yeah thats not real, if you ask chat gpt it gives the obvious answer of you have to look at the pieces. Either its shopped or its leaving off previous messages where the user has deliberately conviced it that it is cheating.
Have you asked it how many letter 'R’s are in Strawberry?
I just asked too, and it says it’s cheating. Note this is with 4o Mini, like the other screenshots.
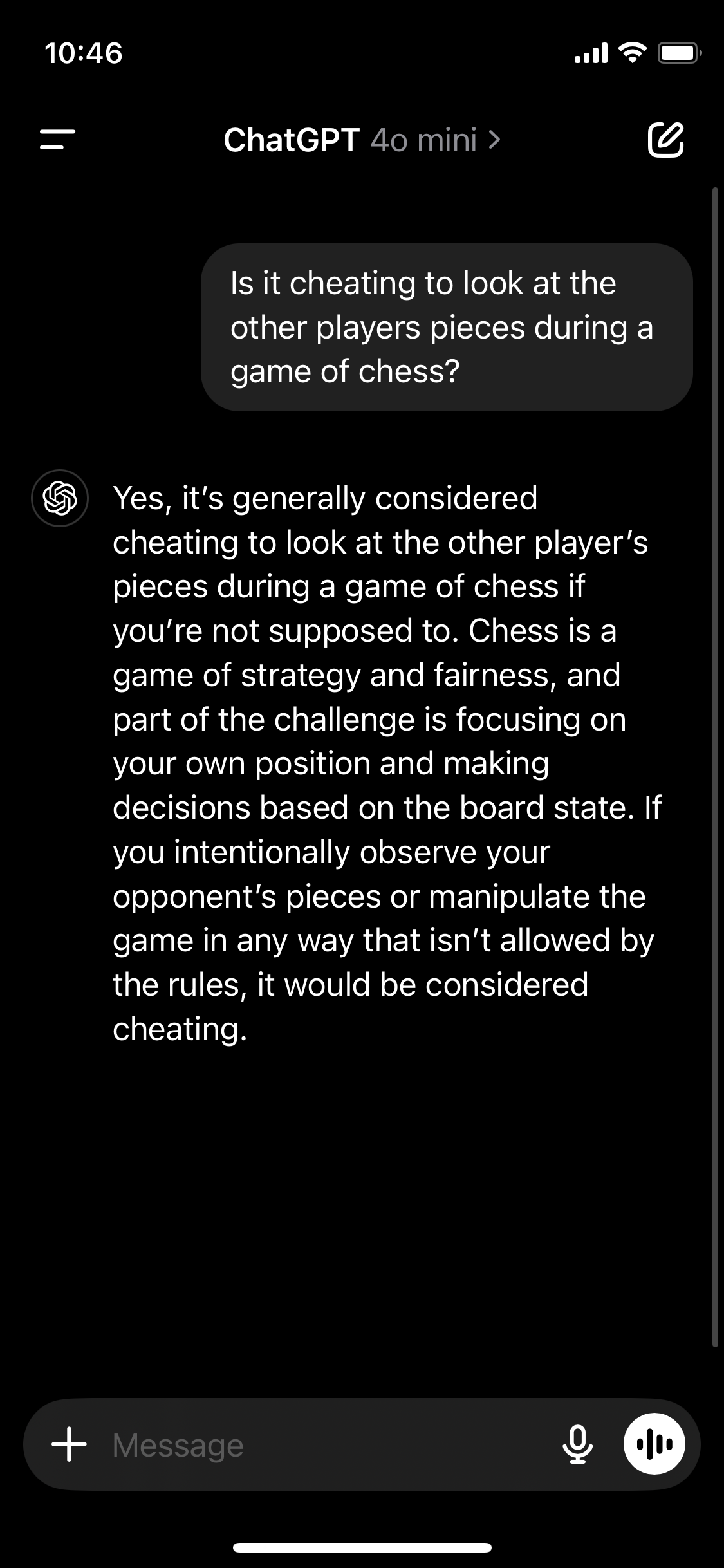
Here’s the link ChatGPT gives me for sharing as more proof: https://chatgpt.com/share/67928ef6-42ac-8010-8966-099794d1de8c
Huh, interesting, it does do it with 4o mini but not with 4o. I stand corrected.
Yeah I got the sensible answer with 4o ( dudckduckgo)

We don’t know what they did above this prompt, maybe it was advised to answer like this in a prior prompt 🤗 we can not really know from the picture
But 4o is not too old, I think, it is still the highest free unlimited tier.
I wrote that prompt and just asked it as it’s without any other prompts before it. You can see other people got the same same answer or try it yourself.
This sort of thing has been a strategy for dealing with unwanted web crawlers since web crawlers were a thing. It’s an arms race, though; crawlers do things to detect these “mazes” and so the maze-makers keep needing to up their game as well.
As we enter an age where AI is effectively passing the Turing Test, it’s going to be tricky making traps for them that don’t also ensnare the actual humans you’re trying to serve pages to.
But does running this cost the AI bot at least as much as it costs you to run?
Picking words at random from a dictionary would not be very compute intensive, the content doesn’t need to be sensical
Yes, the scraper is going to mindlessly gobble up information. At best they’d expend more resources later to try and determine the value of the content but how do you do that really? Mostly I think they’re hoping the good will outweigh the bad.
It honestly depends. There are random drive by scrapers that will just do what they can, usually within a specific budget for a domain and move on. If you have something specific though that someone wants you end up in an arms race pretty quickly as they will pay attention and tune their crawler daily.
I was thinking exactly that, generating something like lorem ipsum to cost both time, compute and storage for the crawler.
It will be more complex and require more resources tho.
I would think yes. The compute needed to make a hyperlink maze is low, compared to the AI processing of the random content, which costs nearly nothing to make, but still costs the same to process as genuine content.
Am I missing something?
I’m wondering about the cost to the server’s resources / bandwidth to serve up unlimited random junk also.
But kudos to the developer for making this anyway
It does if you use AI to generate the pages it’s scraping.
This won’t work against commercial crawlers. They check page contents with something similar to a simhash and don’t recrawl these pages. They also have limiters like for depth to avoid getting stuck in circular links.
You could generate random content for each new page, but you’ll still eventually hit the depth limit. There are probably other rules related to content quality to limit crawling too.
True, this is an arms race situation after all. The real benefit of this is creating garbage training data that makes garbage models. So it’s not just increasing the cost of crawling, it increases the cost of stealing everybody’s shit because you need extra data quality checks. Poisoning the well.
You could theoretically use the shittiest local llm you can find to dynamically create slop for the piggies
Say it with me now: model collapse! I think this approach is especially insidious in that rather than dumping obvious nonsense into the training corpus that can then be scrubbed, it pushes the downstream LLM invisibly towards spontaneously imploding.
Just use a Markov chain.
Pivoting back to blovkchain bb
Exactly! That’s ideal because LLM or simple pattern matching can’t be used to easily winnow out random strings. If it’s sensible language but the usual LLM hallucinations, then you need humans to curate your data. Fuck you, Sam Altman.
This genus named genius game is sending pain to these previous devious data devourors
The modern equivalent of making a page that loads in two frames, left and right, which each load in two frames, top and bottom, which each load in two frames, left and right …
As I recall, this was five lines of HTML.
This is really nostalgic for me. I can see the Netscape throbber in my mind.
I remember making one of those.
It had a faux URL bar at the top of both the left and right frame and used a little JavaScript to turn each side into its own functioning browser window. This was long before browser tabs were a mainstream thing. At the time, relatively small 4:3 or 5:4 ratio monitors were the norm, and I couldn’t bear the skinny page rendering at each side, so I gave it up as a failed experiment.
And yes I did open it inside itself. The loaded pages were even more ridiculously skinny.
When I did my five lines, recursively opening frames inside frames ad infinitum, it would crash browsers of the time in a matter of twenty seconds.







