

- cross-posted to:
- technology@beehaw.org
- cross-posted to:
- technology@beehaw.org
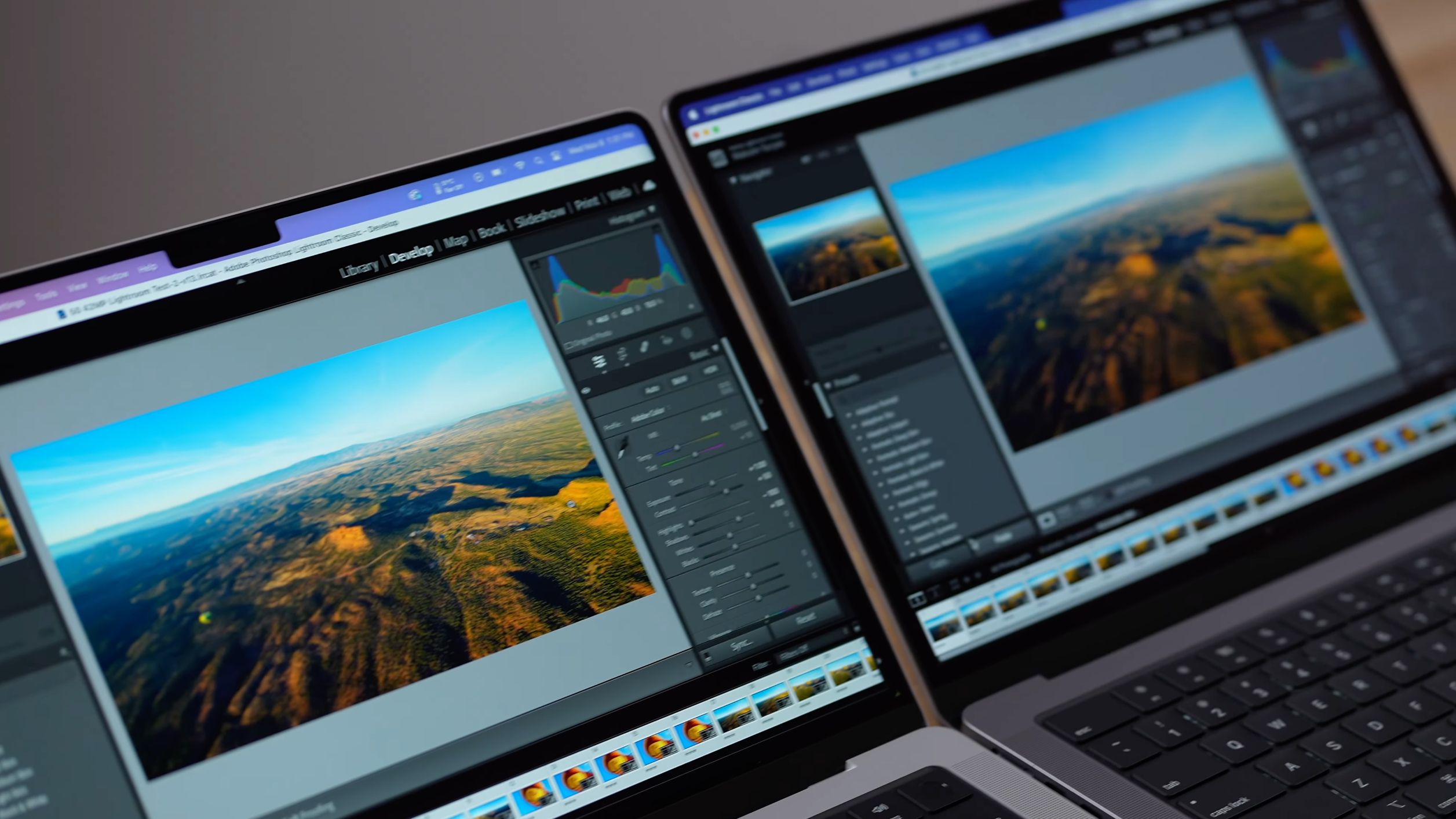
8GB RAM in M3 MacBook Pro Proves the Bottleneck in Real-World Tests::Apple’s new MacBook Pro models are powered by cutting-edge M3 Apple silicon, but the base configuration 14-inch model starting at $1,599…
What’s worse is that their “8GB = 16GB” claim has a tiny bit of truth in it: many apps that are GPU-accelerated usually load/generate stuff on host RAM and then transfer it to the GPU RAM to launch some shaders/kernels on it and they do this repeatedly. The idea with Apple (also AMD when you consider APUs) is that since the RAM is “unified” you just have one RAM and you probably don’t have that redundancy anymore if those apps are built with that in mind, so in a sense if previously you had a 1GB buffer that had to live on both CPU and GPU RAM, this time it will only live in as a single 1GB buffer on Apple’s “unified” RAM. That’s still very different from the “8GB = 16GB” deceptive marketing by Apple.
You don’t have to put unified in quotes, it’s the proper term for an SoC that shares the same memory between the CPU and GPU.
The major advantage of unified memory is that it doesn’t have the copy overhead. When using a discrete GPU you need to load data onto the host and then copy it over to the GPU. And then if data on the GPU needs to be processed separately by the CPU (saved to a file, sent over the network, etc) you incur more overhead again. And let’s ignore more specific technologies like Direct I/O and io_uring for this discussion.
On an SoC with unified memory you don’t have this overhead. The CPU can (in theory) access the same memory space as the GPU with zero overhead, and it makes the performance hit from shuttling the data back and forth non-existent.
But there’s a massive downside, and it’s that it drastically cuts down your available memory, because now the CPU and GPU have only a single 8GB pool to use for both. Whereas in a system without unified memory and a discreet GPU would have the 8GB for the CPU in addition to whatever the GPU has. They don’t step on each other’s toes.
For example, if I use a system with 8GB of host RAM and a GPU with 6GB of VRAM to run a model of some kind (let’s say stable diffusion), it will load the model into the VRAM and not clog up the host RAM. Yes, the host will initially use system RAM to load the file descriptors and then shuttle the data to the GPU, but once that’s done the model isn’t kept on the host.
On a Mac it would load it onto the only memory available and the CPU would not have the full 8GB available to it the way an x86 system would have.
The point I’m making is that because of the unified architecture the 8GB is effectively even less than 8GB in a discrete GPU system. It’s worse.