It’s U+E001 from a Private Use Area. The UnicodePad app renders it as something between 鉮 and 鋁 (separate boxes stricken through; I wasn’t able to find it even with Google Lens)
I swear to god,someone must have written an intermediary language between regex and actual programming, or I’m going to eventaully do it before I blow my fucking brains out.
How do you think that would look? Regex isn’t particularly complicated, just a bit to remember. I’m trying to picture how you would represent a regex expression in a higher level language. I think one of its biggest benefits is the ability to shove so much information into a random looking string. I suppose you could write functions like, startswith, endswith, alpha(4), or something like that, but in the end, is that better?
There’s a built-in feature that Perl has that only a few of the languages claiming PCRE have actually done, and it makes things a lot more readable. The /x modifier lets you put in whitespace and comments. That alone helps a lot if you stick to good indentation practices.
If all other code was written like an obfuscated C contest, it would be horrible. For some reason, we put up with this on regex, and we don’t have to.
I agree, but then there’s also some other niceties that come from expression parsers in the language itself (as noted in the article): syntax highlighting, LSP, a more complete AST for editors like helix.
Syntax highlighting works fine as long as your language has a way to distinguish regexes from common strings. Another place where Perl did it right decades ago and the industry ignored it.
Nah, the language itself should be as simple as possible. Bloating it with endless extensibility and features is exactly what makes Perl a write-only language in many cases and why it is becoming less and less relevant with time.
Assuming “text” in your example is a placeholder for a 5 digit alpha string, it can be written like this in regex: /[a-zA-Z0-9]{5}/
If ”text" is literal, then your statement is impossible.
I think that when it gets to more complex expressions like a phone number with country code that accepts different formats, the verbosity of a higher level language will be more confusing, or at least more difficult to take in quickly.
Exactly. It’s a lot like Java to me. Looks readable on the surface, but it’s actually adding a bunch of crap you don’t need and does not help anything.
They also have to implement a long list of features. These projects tend to focus on the handful of features the authors specifically use, and the rest get sent by the wayside. Taking the Melody language that was mentioned in another message, it hasn’t even fully implemented[^A] or [abc]. We’re not even talking about somewhat obscure stuff like zero width assertions or lookaheads. These are very basic.
The “something” is where the regex goes. For simple cases contains by itself does just fine, but for almost anything kind of dynamic input, it’s going to not be capable of what regex does.

{kind=link}
Just outta curiosity:
Full o1 model
Claude 3.5 Haiku:
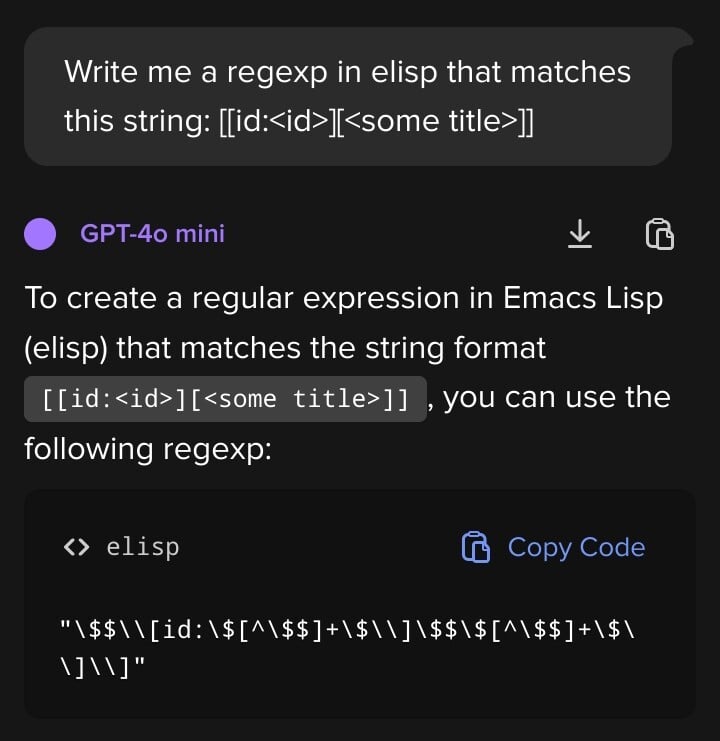
Never used elisp, no idea of any of this is right lmao
Claude at least created an elisp function that looks ok
3.5 sonnet might do a lot better, idk I’m on the free plan with Claude lmao
o1 without Markdown misformatting:
No idea what the rectangles are supposed to be, I just copy-pasted it
They are valid unicode points that your font doesn’t know about.
… or at least they represent that, but I think there’s a character that looks like one too.
It’s U+E001 from a Private Use Area. The UnicodePad app renders it as something between 鉮 and 鋁 (separate boxes stricken through; I wasn’t able to find it even with Google Lens)
I swear to god,someone must have written an intermediary language between regex and actual programming, or I’m going to eventaully do it before I blow my fucking brains out.
How do you think that would look? Regex isn’t particularly complicated, just a bit to remember. I’m trying to picture how you would represent a regex expression in a higher level language. I think one of its biggest benefits is the ability to shove so much information into a random looking string. I suppose you could write functions like, startswith, endswith, alpha(4), or something like that, but in the end, is that better?
People have unironically done that. No, it isn’t better. The fundamental mental model is the same.
I want to see their unironic attempts, maybe they’re useful to me at least if they’re not better.
It’s not the fundemental model that I have a problem with for Regex, it’s the fucking brainfuck tier syntax
Here’s one example
I honestly think it can be a lot more readable, especially when the regex would have been in the thousands of characters.
There’s a built-in feature that Perl has that only a few of the languages claiming PCRE have actually done, and it makes things a lot more readable. The
/xmodifier lets you put in whitespace and comments. That alone helps a lot if you stick to good indentation practices.If all other code was written like an obfuscated C contest, it would be horrible. For some reason, we put up with this on regex, and we don’t have to.
https://wumpus-cave.net/post/2022/06/2022-06-06-how-to-write-regexes-that-are-almost-readable/index.html
I agree, but then there’s also some other niceties that come from expression parsers in the language itself (as noted in the article): syntax highlighting, LSP, a more complete AST for editors like helix.
Syntax highlighting works fine as long as your language has a way to distinguish regexes from common strings. Another place where Perl did it right decades ago and the industry ignored it.
Nah, the language itself should be as simple as possible. Bloating it with endless extensibility and features is exactly what makes Perl a write-only language in many cases and why it is becoming less and less relevant with time.
yes.
YES.
startswith('text'); lengthMustBe(5); onlyContain(CHARSETS.ALPHANUMERICS); endswith('text');is much more legible than []],[.<{}>,]‘text’[[]]][][)()(a-z,0-9){}{><}<>{}‘text’{}][][
Assuming “text” in your example is a placeholder for a 5 digit alpha string, it can be written like this in regex: /[a-zA-Z0-9]{5}/
If ”text" is literal, then your statement is impossible.
I think that when it gets to more complex expressions like a phone number with country code that accepts different formats, the verbosity of a higher level language will be more confusing, or at least more difficult to take in quickly.
Exactly. It’s a lot like Java to me. Looks readable on the surface, but it’s actually adding a bunch of crap you don’t need and does not help anything.
They also have to implement a long list of features. These projects tend to focus on the handful of features the authors specifically use, and the rest get sent by the wayside. Taking the Melody language that was mentioned in another message, it hasn’t even fully implemented
[^A]or[abc]. We’re not even talking about somewhat obscure stuff like zero width assertions or lookaheads. These are very basic.string.contains("something")Just do that repeatedly
The “something” is where the regex goes. For simple cases contains by itself does just fine, but for almost anything kind of dynamic input, it’s going to not be capable of what regex does.
You’re right, but it was a joke.
It’s called Haskell.