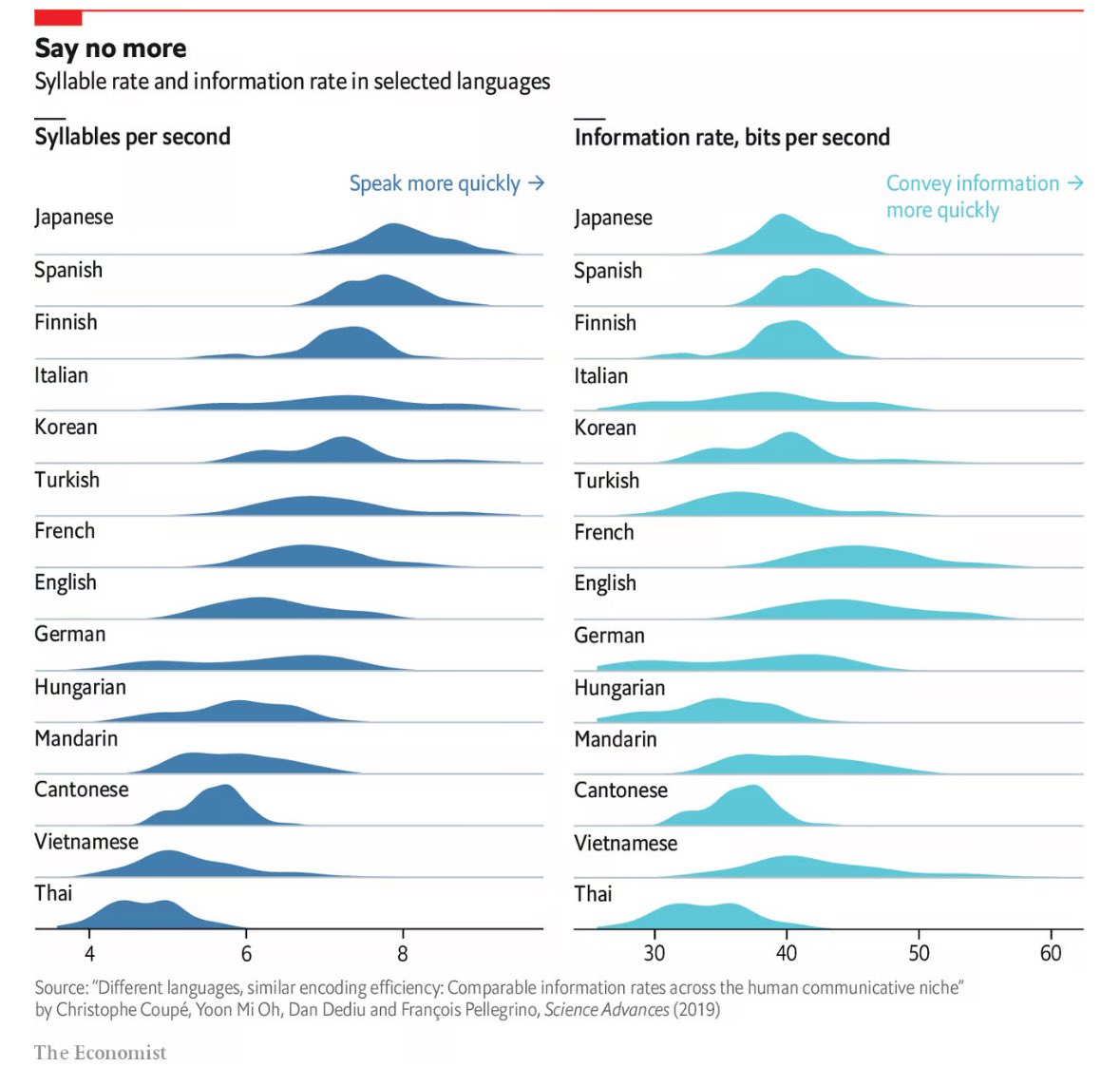
So I did a quick pass through the paper, and I think it’s more or less bullshit. To clarify, I think the general conclusion (different languages have similar information densities) is probably fine. But the specific bits/s numbers for each language are pretty much garbage/meaningless.
First of all, speech rates is measured in number of canonical syllables, which is a) unfair to non-syllabic languages (e.g. (arguably) Japanese), b) favours (in terms of speech rate) languages that omit syllables a lot. (like you won’t say “probably” in full, you would just say something like “prolly”, which still counts as 3 syllables according to this paper).
And the way they calculate bits of information is by counting syllable bigrams, which is just… dumb and ridiculous.

{kind=link}
So I did a quick pass through the paper, and I think it’s more or less bullshit. To clarify, I think the general conclusion (different languages have similar information densities) is probably fine. But the specific bits/s numbers for each language are pretty much garbage/meaningless.
First of all, speech rates is measured in number of canonical syllables, which is a) unfair to non-syllabic languages (e.g. (arguably) Japanese), b) favours (in terms of speech rate) languages that omit syllables a lot. (like you won’t say “probably” in full, you would just say something like “prolly”, which still counts as 3 syllables according to this paper).
And the way they calculate bits of information is by counting syllable bigrams, which is just… dumb and ridiculous.